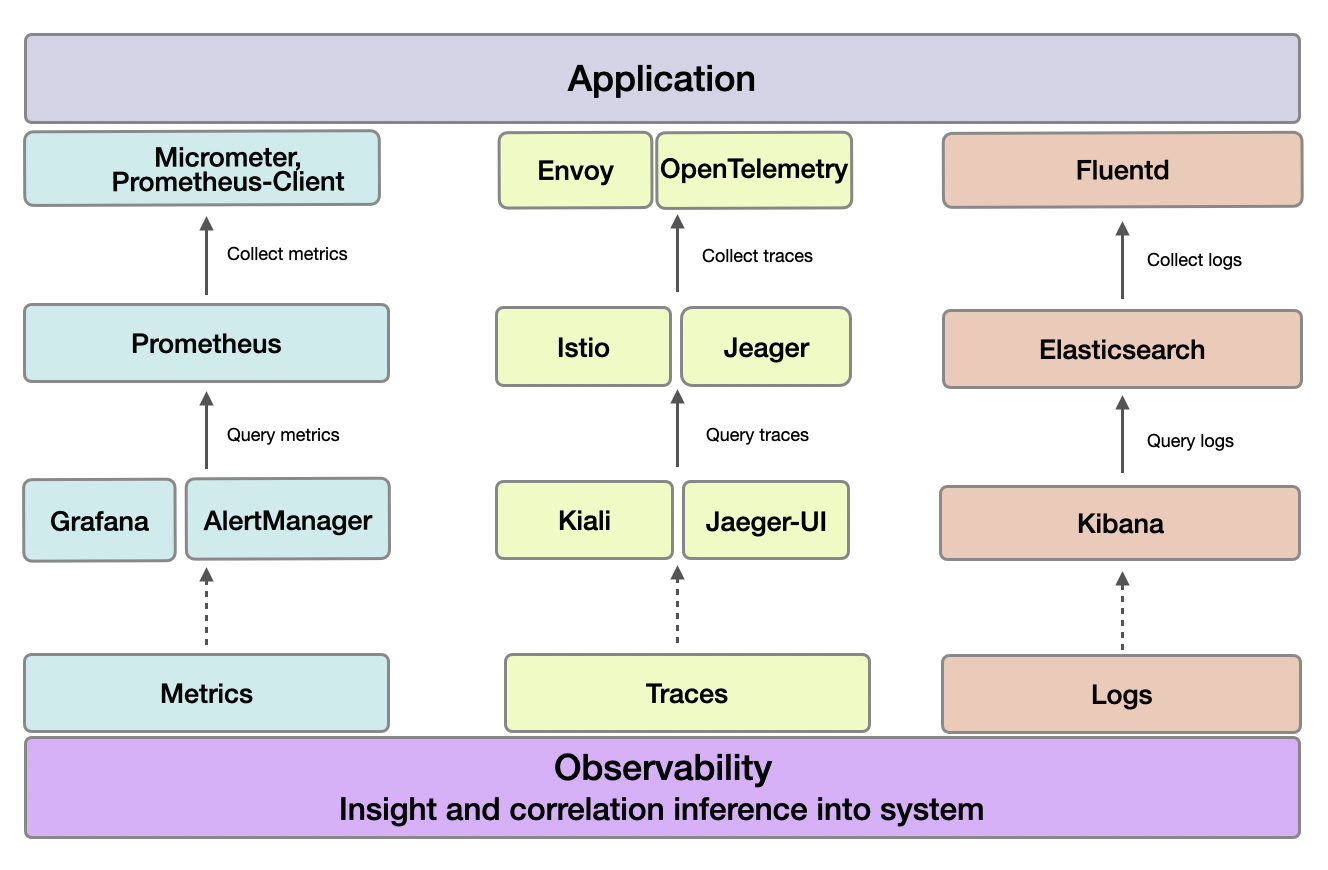
클라우드 환경에서의 빠른 대응과 안정적 운영을 위해서는 단순한 모니터링을 넘어, 시스템 내부 상태를 관찰하고 예측할 수 있는 능력이 필수적입니다. CNAP의 Observability는 로그, 메트릭, 트레이스를 기반으로 전체 시스템의 동작을 통합적으로 파악하고, 문제를 조기에 인지하고 자동화된 대응까지 확장할 수 있도록 지원합니다.
성능, 상태분석 및 알림 – Metrics
메트릭(Metrics)은 시스템의 상태와 성능을 숫자로 표현하는 핵심 지표입니다. CPU 사용률, 메모리 소비, 요청 수, 오류율과 같은 지표들은 서비스의 안정성과 병목을 실시간으로 감지하고 대응을 가능하게 합니다.
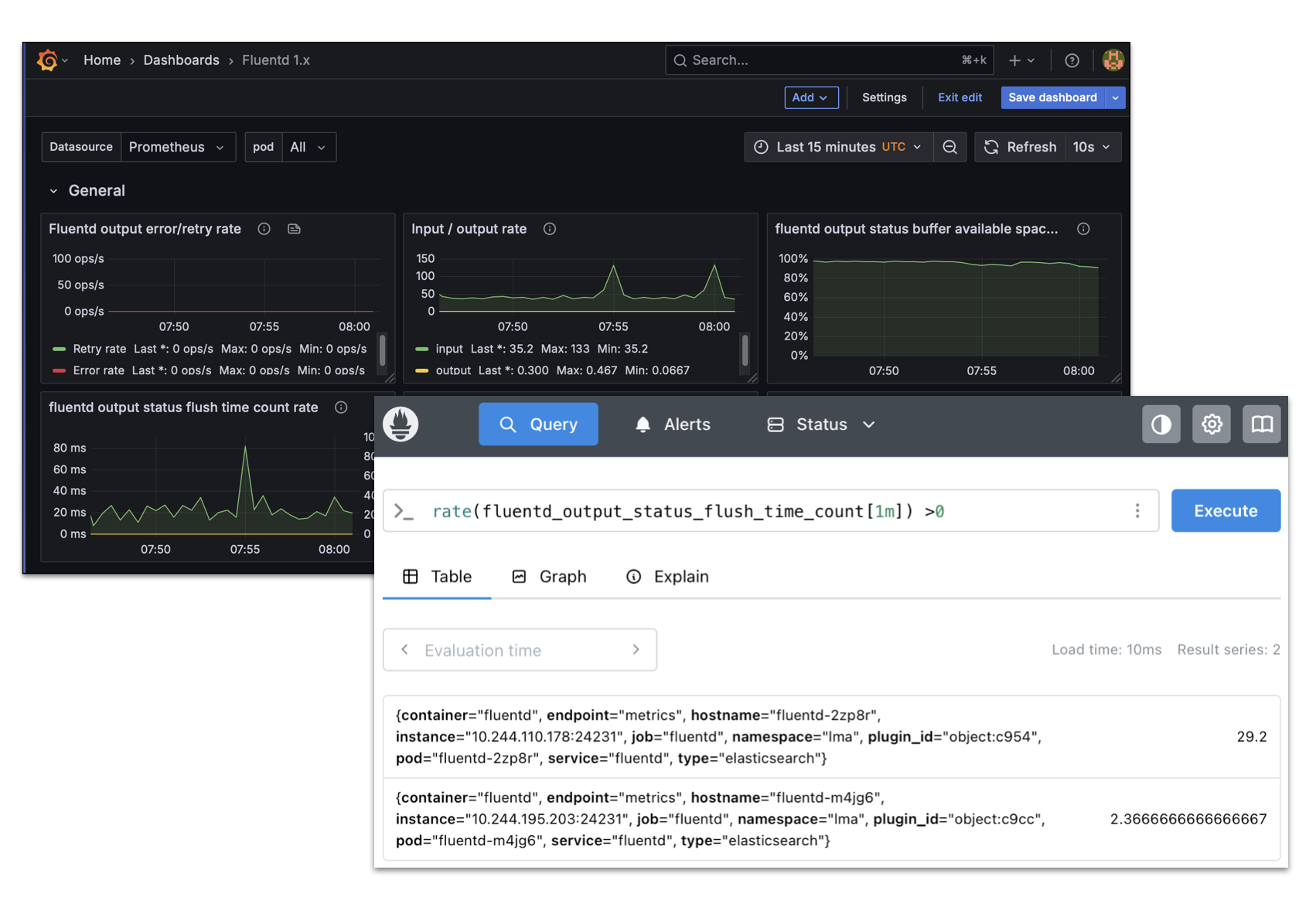
메트릭 수집 및 시각화
Prometheus는 타임 시리즈 기반 시스템을 통해 수집된 메트릭은 대시보드 시각화 및 경보 설정에 활용되어 운영 효율을 극대화합니다. 시스템의 '심장박동'을 읽듯, 메트릭을 통해 서비스 상태를 끊임없이 파악할 수 있습니다.
Notification
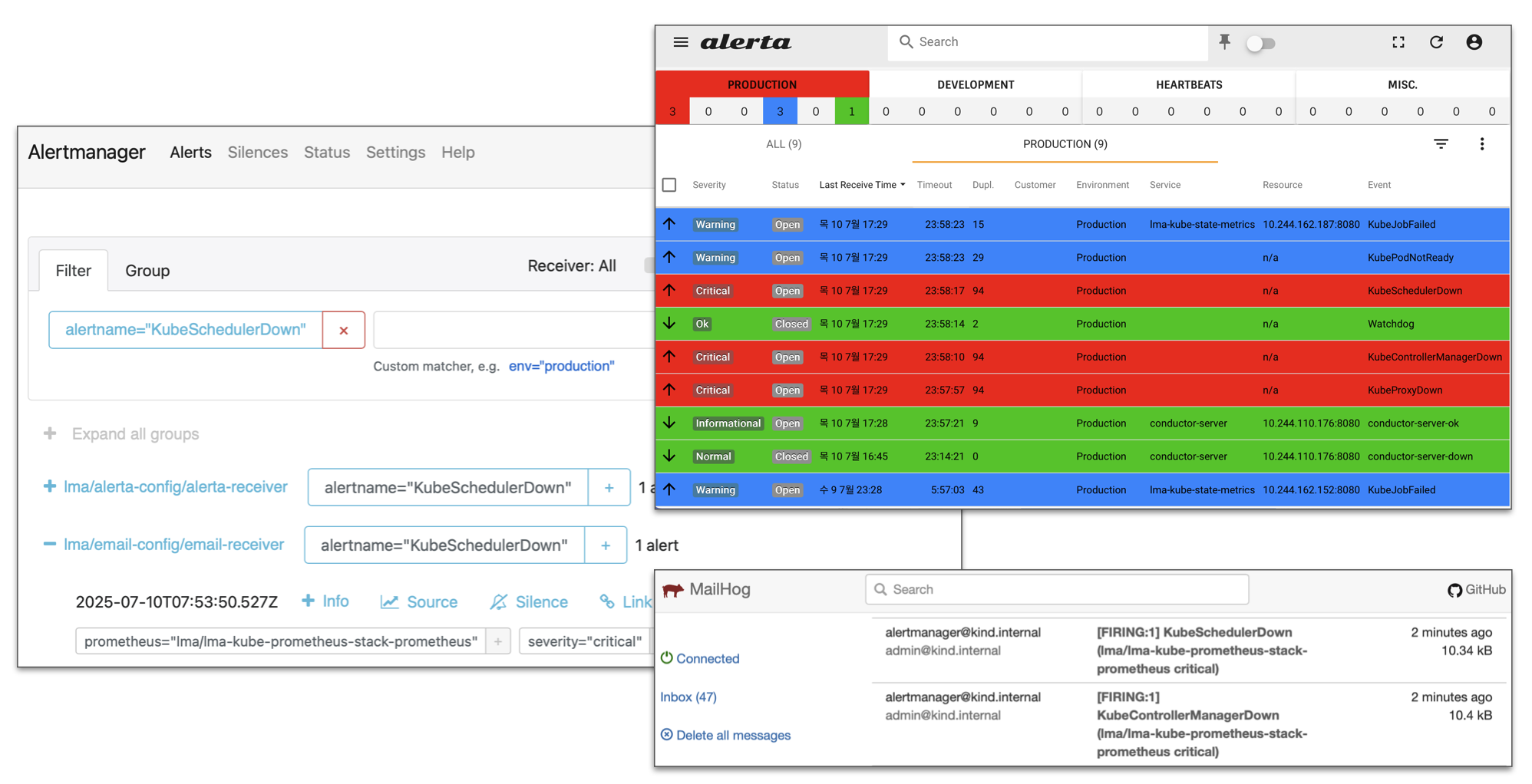
Prometheus는 수집한 메트릭을 가지고 정해진 조건에 따라 알림을 생성합니다. Alertmanager는 이 알림을 묶고, 노이즈를 줄이며, Slack, 이메일 등 다양한 채널로 전달해 운영자의 빠른 대응을 돕습니다. 단순한 수집을 넘어, 실시간 감시와 자동화된 경고 체계를 제공합니다.
API 호출 흐름 추적 – Traces
트레이스(Traces)는 하나의 요청이 여러 서비스와 컴포넌트를 거치며 처리되는 경로를 시각적으로 보여줍니다. 각 단계의 지연 시간과 호출 관계를 파악함으로써, 병목 구간이나 실패 지점을 빠르게 식별할 수 있습니다.
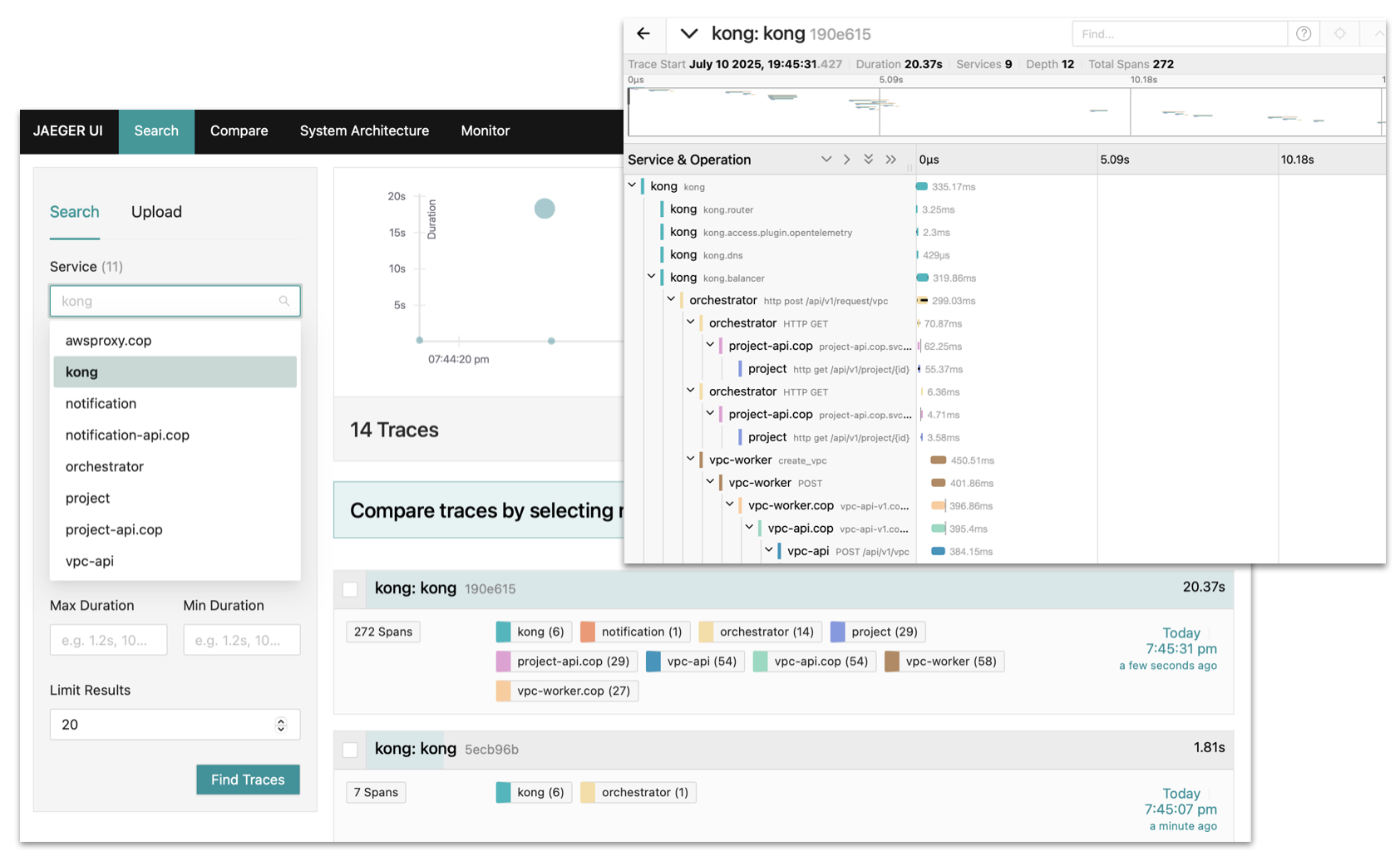
API 분산 추적
OpenTelemetry와 Jaeger로 구성된 분산 추적 시스템은 요청 단위의 상세한 흐름을 기록하고 분석함으로써 복잡한 마이크로서비스 아키텍처에서도 원인 파악과 성능 개선을 손쉽게 만듭니다. 단편적인 지표를 넘어서, 서비스 전반의 '연결된 흐름'을 Traces로 확인할 수 있습니다.
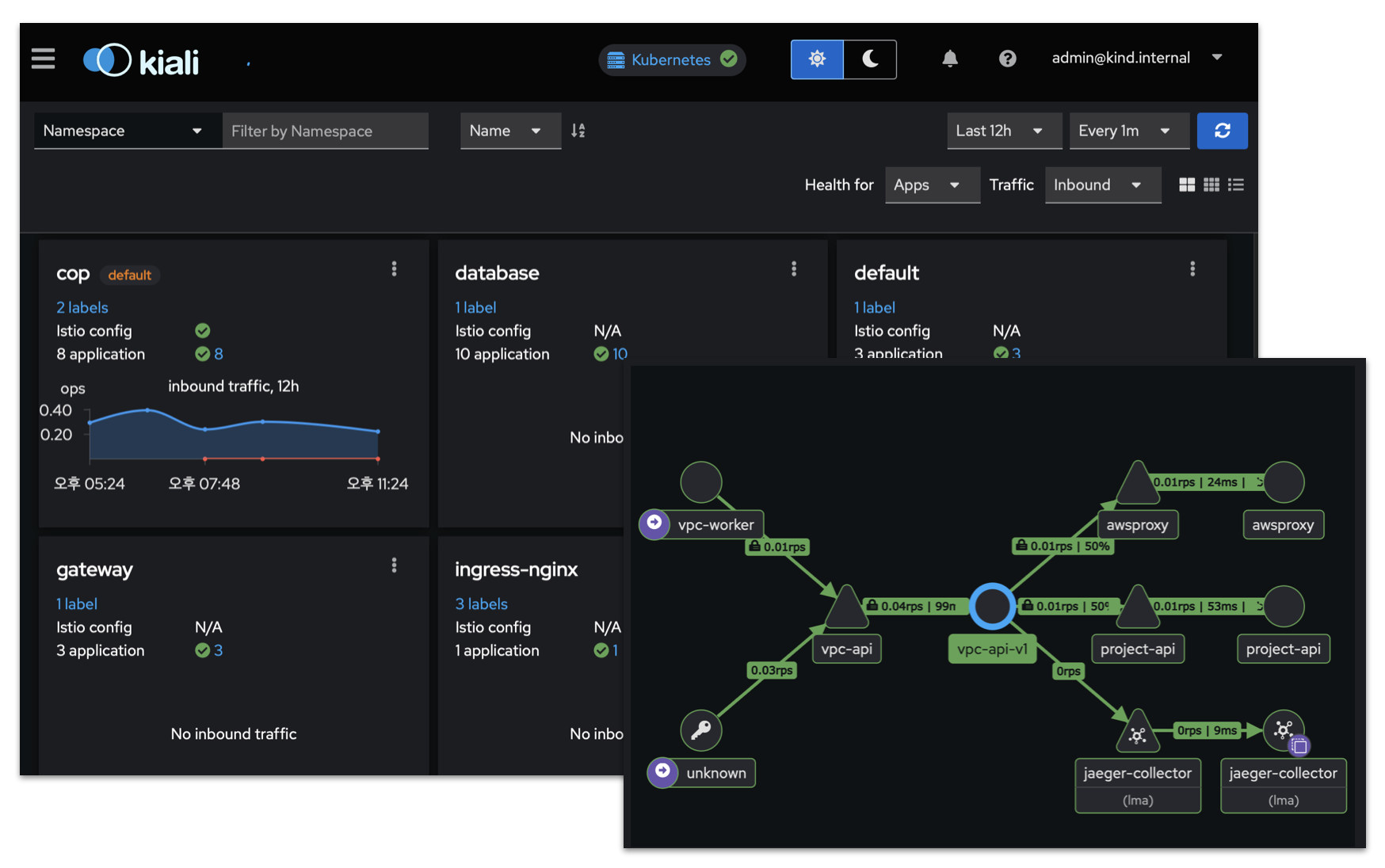
서비스 메시 트래픽
Kiali는 서비스 메시에 흐르는 트래픽을 시각적으로 표현함으로써 복잡한 마이크로서비스 간의 상호작용을 한눈에 파악할 수 있게 해줍니다. 서비스 간 연결 상태, 지연, 실패율 등을 실시간으로 보여주어 문제의 원인을 빠르게 찾아내고, 네트워크 흐름을 효과적으로 관리할 수 있습니다.
로그 분석 – Logs
로그(Logs)는 시스템과 애플리케이션에서 발생하는 모든 로그를 시간 순서대로 기록합니다. 오류, 경고, 정보 메시지 등 다양한 로그는 문제 발생 시 상세한 상황 파악과 원인 분석에 필수적입니다.
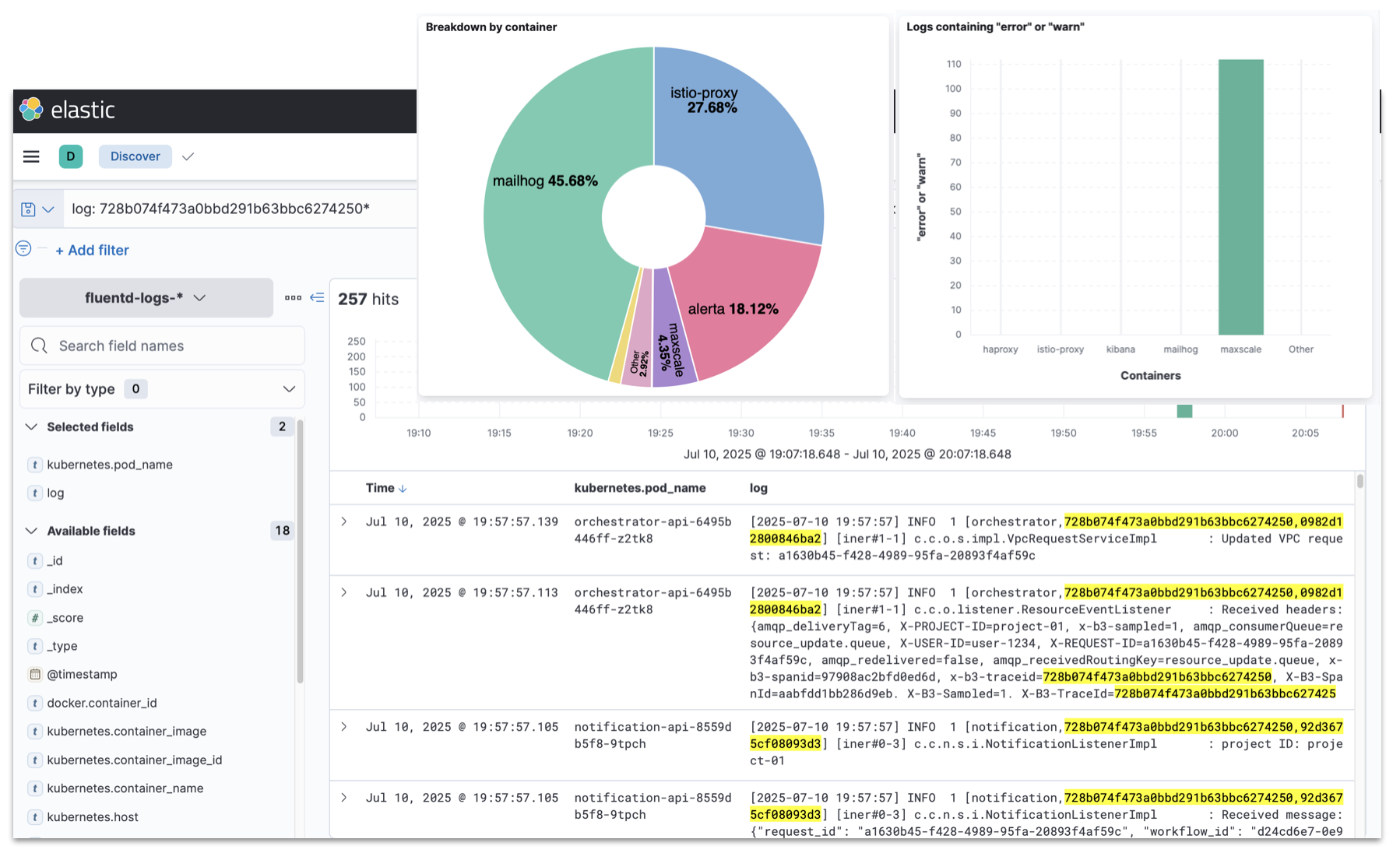
Elasticsearch, Fluentd, Kibana로 구성된 관리 도구를 활용하면 대량의 로그 데이터를 효율적으로 수집, 검색, 시각화할 수 있습니다. 로그를 통해 시스템 내부의 ‘상태’를 파악하고, 문제 해결과 운영을 최적화할 수 있습니다.